Главная страница
Представленные ниже виджеты используют следующие метки (лейблы) для классификации ресурсов:
- On-Prem - виджет использует данные, собираемые с локальных инфраструктур.
- Cloud - виджет использует данные, собираемые из облачных сред (Яндекс.Облако).
- On-Prem & Cloud — виджет объединяет и отображает данные из обоих типов инфраструктур.
Рекомендованные действия (Recommended Actions)
Данный виджет предназначен для визуального сравнения текущего состояния ресурсов вашего окружения (виртуальные машины, диски) с прогнозируемым состоянием после применения рекомендованных системой оптимизаций.
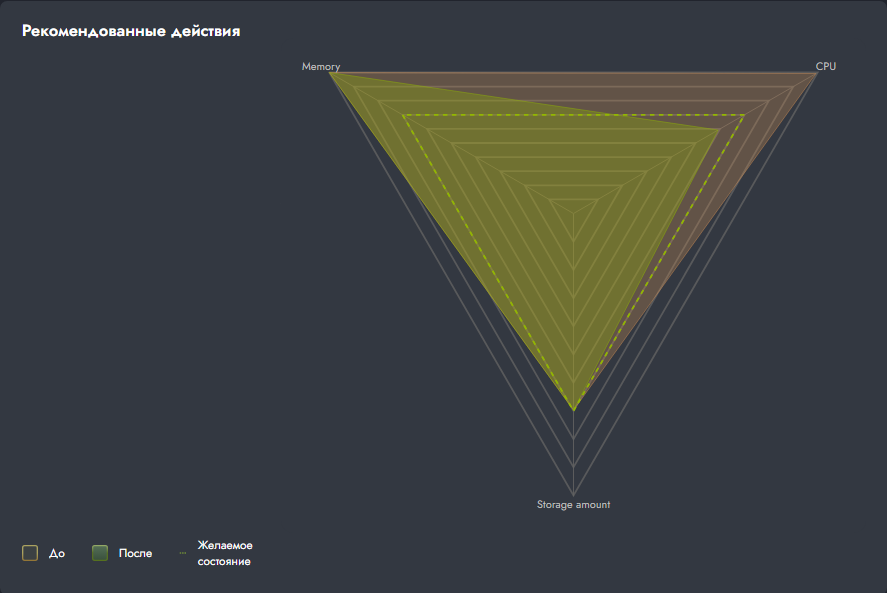
Для общего сравнения используется радиальная схема, на которой отображены три ключевые метрики:
- CPU (выделенные потребителям процессорные ресурсы);
- Memory (суммарно выделенный объем оперативной памяти);
- Storage amount (объем выделенного хранилища под диски ВМ).
Интерпретация диаграммы:
- Коричневая область (До) отражает текущий уровень выделенных ресурсов для потребителей.
- Зеленая область (После) показывает прогнозируемое состояние после выполнения рекомендаций.
Экономия затрат (Cost savings)
Виджет имеет 2 раздела: * Потенциальная экономия * Экономия затрат
Потенциальная экономия:
Виджет предоставляет информацию о том, как можно перераспределить расходы на эксплуатацию текущего окружения без ущерба для качества и надежности предоставляемых услуг.
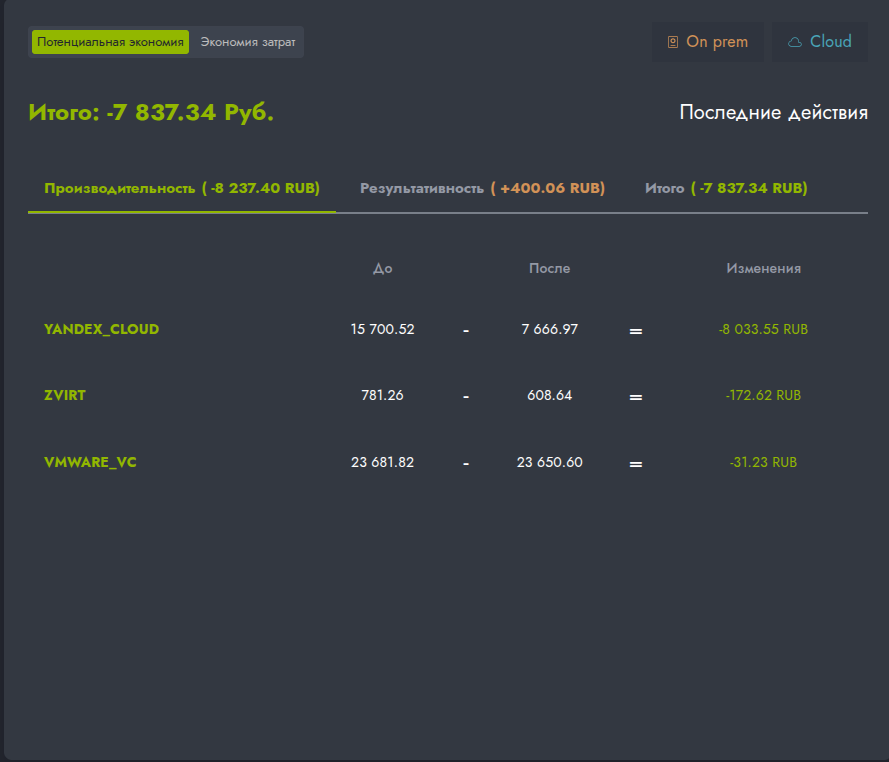
Анализ представлен в трех вкладках, каждая из которых фокусируется на определенном аспекте оптимизации.
Важно: Расчет стоимости учитывает суммарную стоимость всех вычислительных ресурсов на определенные типы таргетов, в частности CPU, Memory.
1. Эффективность (Efficiency).
Отражает эффективность использования ресурсов и экономию средств при текущей нагрузке.
- До: Отображает текущую стоимость задействованных аппаратных ресурсов(CPU, Memory) в выбранной валюте. Расчет основан на фактическом выделении ресурсов без учета оптимизации. Подробная схема расчета представлена ниже в разделе "Схема расчета".
- После: Показывает прогнозируемую стоимость окружения после выполнения рекомендаций системы. Значения отражают оптимальное использование ресурсов без потери производительности.
- Изменения: Указывает, какую стоимость ресурсов в выбранной валюте можно сохранить в результате оптимизации.
2. Производительность (Performance).
Демонстрирует изменение стоимости ресурсов после оптимизации системы с учетом необходимости выделения дополнительных ресурсов, для поддержания заданного уровня загрузки.
- До: Текущая стоимость аппаратных ресурсов (CPU, Memory) в валюте, рассчитанная по методике из раздела «Схема расчета».
- После: Стоимость ресурсов окружения после выполнения рекомендаций. Отображает затраты необходимые для повышения запаса прочности критически нагруженных систем.
- Изменения: Показывает прирост стоимости аппаратных ресурсов в выбранной валюте.
3. Итого (Total). Объединяет результаты вкладок «Эффективность» и «Производительность», выводит общий результат.
Экономия затрат:
Виджет позволяет за заданный пользователем период рассчитать итоговую экономию или дополнительные траты на инфраструктуру, которые возникли в результате применения рекомендаций по оптимизации.
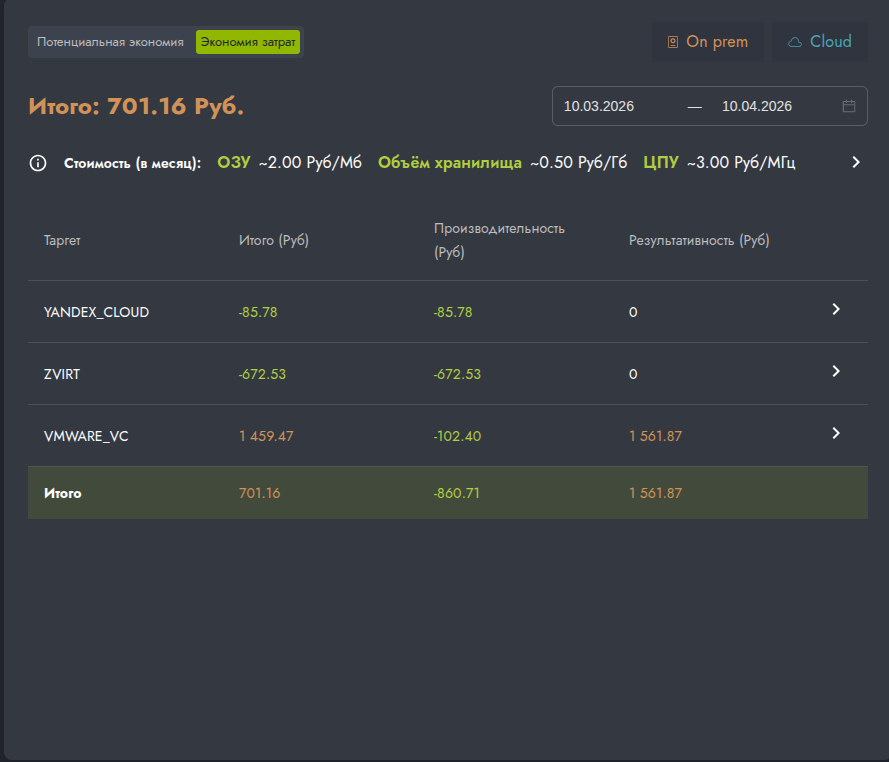
Ключевые особенности: - Расчёт показывает эффект только от применённых на платформе рекомендаций. - Цены в отчёте — это средние цены по всем объектам инфраструктуры за выбранный период. - Изменения стоимости суммируются накопительно от начала до конца периода. - Учитываются как положительные изменения (экономия), так и дополнительные траты связанные с увеличением ресурсов.
Ограничения - Нельзя создавать пользовательские цены для групп, где пересекаются объекты.
График эконономии затрат
Виджет показывает динамику экономии или дополнительных затрат на инфраструктуру за выбранный период.
Расчёт основан на применённых рекомендациях по оптимизации инфраструктуры в Octopus и учитывает изменения ёмкости (capacity) ресурсов на стороне гипервизора. Пользователь задаёт период (дату начала и дату окончания) и выбирает тип таргета (например, VMware, Yandex Cloud).
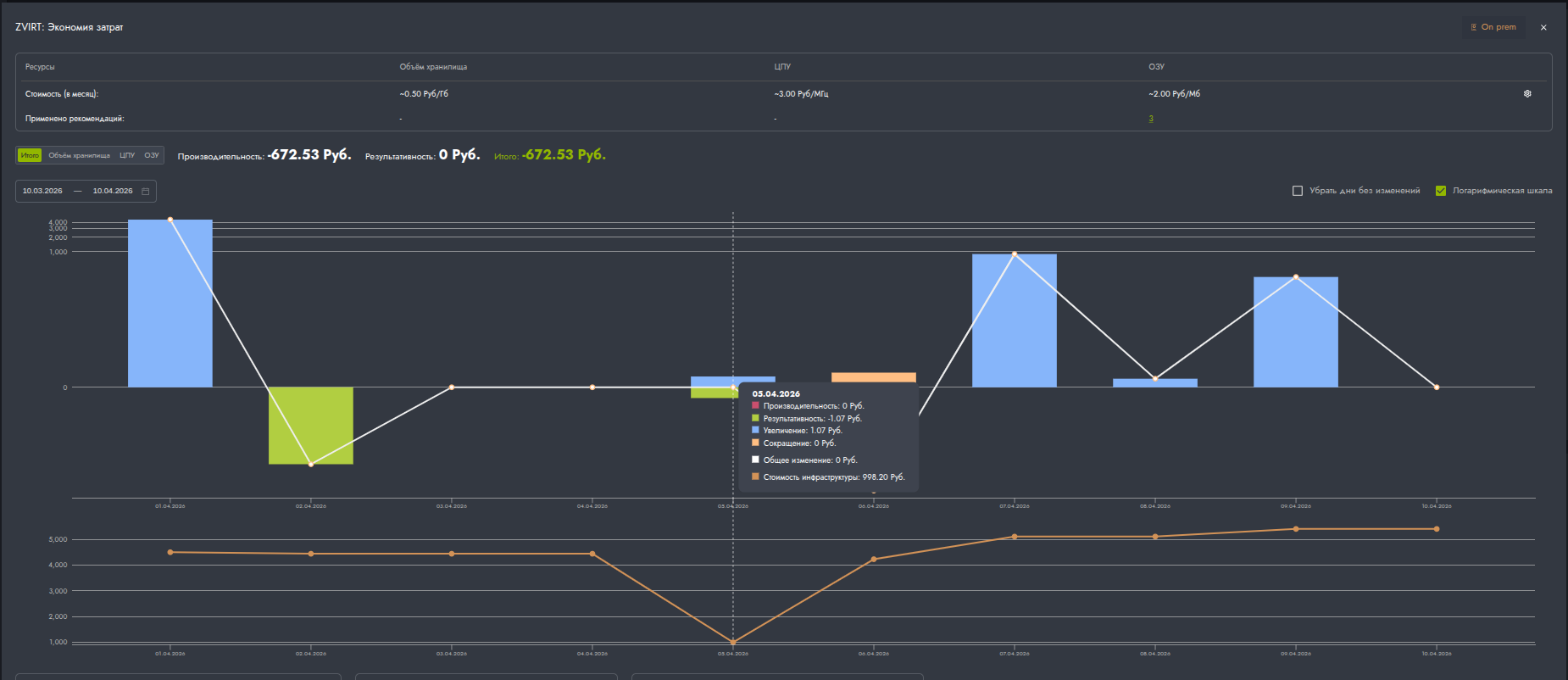
Что показывает интерфейс
- Верхняя панель: средние цены по ресурсам (CPU, Storage, Memory и т.д.) для объектов выбранного типа таргета.
- Кнопки переключения между Total / CPU / Storage amount / MEMORY
- Итоговые значения: Efficiency, Performance, Total
- Верхний график (белая линия) — ежедневные изменения затрат
- Блоки верхнего графика - отражают стоимость изменений как на стороне Octopus(рекомендации), так и на стороне гипервизора(внешние изменения).
- Нижний график (оранжевая линия) — динамика общей стоимости инфраструктуры
Ключевые особенности
- График отражает ежедневную динамику затрат с учётом применённых рекомендаций и действий пользователя.
- Разделяет изменения на «Efficiency» (экономия) и «Performance» (дополнительные траты на увеличение ресурсов).
- Учитывает как автоматические рекомендации платформы, так и ручные изменения пользователя.
- Показывает общее количество применённых рекомендаций.
- Поддерживает логарифмический масштаб и возможность скрывать дни без изменений.
- Для Yandex Cloud на текущий момент учитываются только рекомендации, примененные в Octopus.
- Для Yandex Cloud нет разбивки по ресурсам. Т.к платформа использует шаблоны, указывается стоимость шаблона целиком.
Состояние (Health)
Виджет демонстрирует текущий объем выделенных ресурсов в разрезе таргетов и позволяет оценить потенциальную экономию/оптимизацию за счет применения рекомендаций системы.
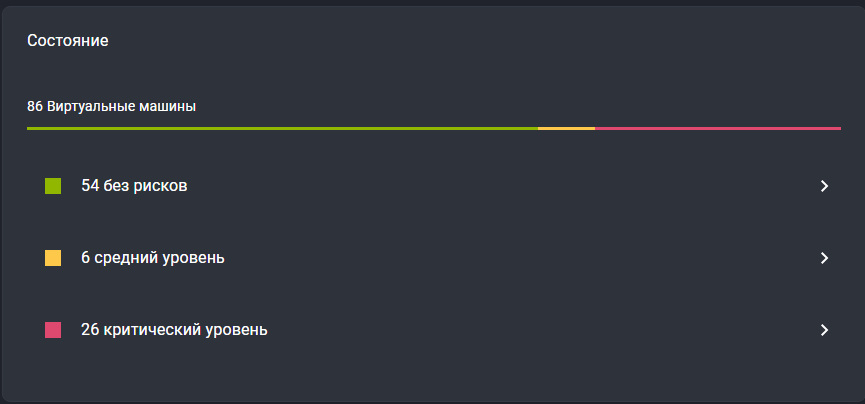
Общее состояние:
- Отображает общее количество виртуальных машин (ВМ) в системе.
-
Визуализирует распределение ВМ по трем уровням риска с помощью цветовой индикации:
- Зеленый цвет - без рисков. ВМ работает в штатном режиме, все критичные метрики в пределах нормы.
- Желтый цвет - средний уровень. Обнаружены отклонения, требующие внимания, но не вызывающие срочного сбоя.
- Красный цвет - критический уровень. Зафиксированы нарушения, которые уже приводят или могут немедленно привести к сбою в работе ВМ.
Каждый из цветовых блоков (зеленый, желтый, красный) является интерактивным. При нажатии на блок происходит переход на страницу «Графы», где открывается предустановленный фильтр, отображающий полный список ВМ, соответствующих выбранному уровню риска.
На странице «Графы» можно получить детальную информацию о каждой ВМ, включая значения конкретных метрик, вызвавших предупреждение, и историю изменений состояния.
Ресурсы (Compute resources)
Виджет демонстрирует текущий объем выделенных ресурсов и позволяет оценить потенциальную экономию/оптимизацию за счет применения рекомендаций системы.
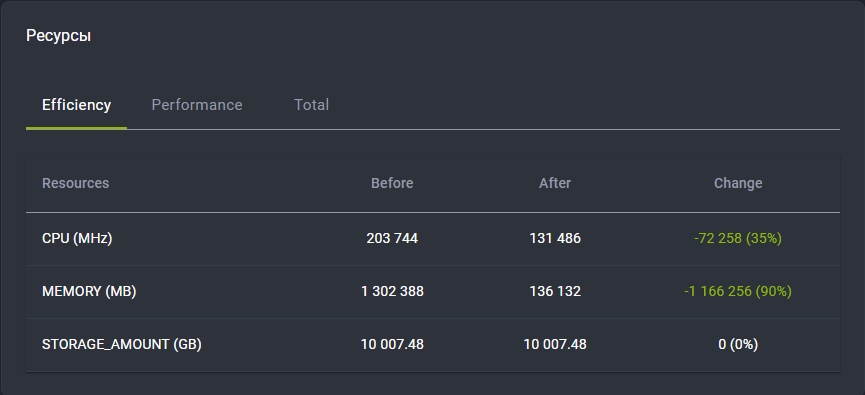
1. Эффективность отображает рекомендации по оптимизации и сокращению ресурсов без потери производительности.
- До — текущее потребление ресурсов.
- После — прогнозируемое потребление после применения рекомендаций по оптимизации.
- Итого — уменьшение значений ресурсов в абсолютных величинах и процентах.
2. Производительность показывает рекомендации по увеличению ресурсов для устранения дефицита производительности.
- До — текущее потребление ресурсов.
- После — рекомендуемые значения для обеспечения стабильной работы.
- Итого — увеличение значений ресурсов в абсолютных величинах и процентах.
3. Итого. Суммирует эффект от всех рекомендаций и показывает общий баланс изменений.
Виджет изменений окружения (As is - To be)
Виджет перехода между состояниями, который предоставляет более подробную информацию о влиянии применения рекомендаций на окружение и аппаратные ресурсы.
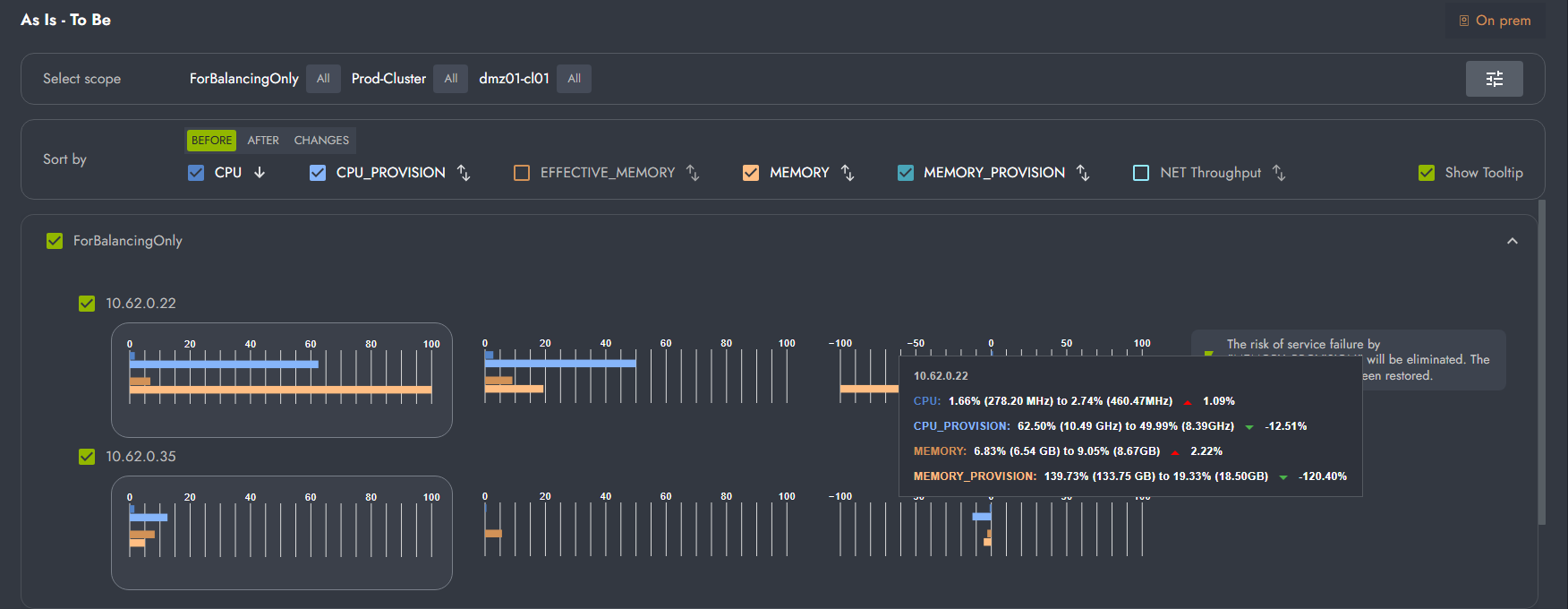
Ключевые метрики фильтрации:
-
CPU — текущая фактическая загрузка процессора
-
CPU_PROVISION — выделенные виртуальные ресурсы CPU (виртуальные ядра, зарезервированные для ВМ)
-
MEMORY — текущее фактическое потребление оперативной памяти
-
MEMORY_PROVISION — выделенная виртуальная память (объем RAM, зарезервированный для ВМ)
-
EFFECTIVE_MEMORY — это комплексная метрика использования памяти, представляющая собой сумму нагрузки на хост и совокупной нагрузки всех виртуальных машин, где для каждой ВМ учитывается значение, максимально приближенное к реальному потреблению памяти приложениями и операционной системой внутри неё. Данные собираются из нескольких источников:
- для большинства гипервизоров используется стандартная метрика загрузки памяти ВМ;
- для VMware применяется подход, аналогичный метрикам vROPS;
- при наличии мониторинга через Zabbix приоритет отдаётся его данным как более точно отражающим внутреннее потребление ВМ.
-
NET Throughput — пропускная способность сетевых интерфейсов.
Структура виджета:
1. Панель управления
Фильтрация хостов:
- выбор всех хостов или конкретных кластеров
- возможность фильтрации по кластерам (например, ForBalancingOnly)
Панель фильтрации метрик:
- CPU, CPU_PROVISION, EFFECTIVE_MEMORY, MEMORY, MEMORY_PROVISION, NET Throughput.
Show Tooltip — включение/выключение подсказок при наведении.
2. Блок "До" (As is)
Отображает текущее состояние инфраструктуры на момент анализа:
- Процентная и абсолютная загрузка ресурсов согласно выбранным метрикам
- Графическое представление распределения нагрузки по хостам
- Фактические значения для каждого хоста в выбранном scope
3. Блок "После" (To be)
Показывает прогнозируемое состояние после применения рекомендаций:
- Прогнозируемое состояние после применения рекомендаций.
- Количество аппаратных ресурсов, которые могут быть высвобождены.
4. Блок "Изменения" - графическая визуализация изменений.
Особенности графика:
- Горизонтальная ось — хосты с показателями загрузки в %.
- Вертикальная ось — метрики свободного места на устройствах в %.
- Интерактивность — при наведении отображаются точные значения текущих и прогнозируемых величин.
5. Блок анализа результатов - текстовое описание эффекта от применения рекомендаций.
К каждому хосту привязываются действия от виртуальных машин:
- ВМ, которые расположены на хосте
- ВМ, которые должны мигрировать на хост
Кнопка "Применить" открывает детальный список действий для выбранных хостов.
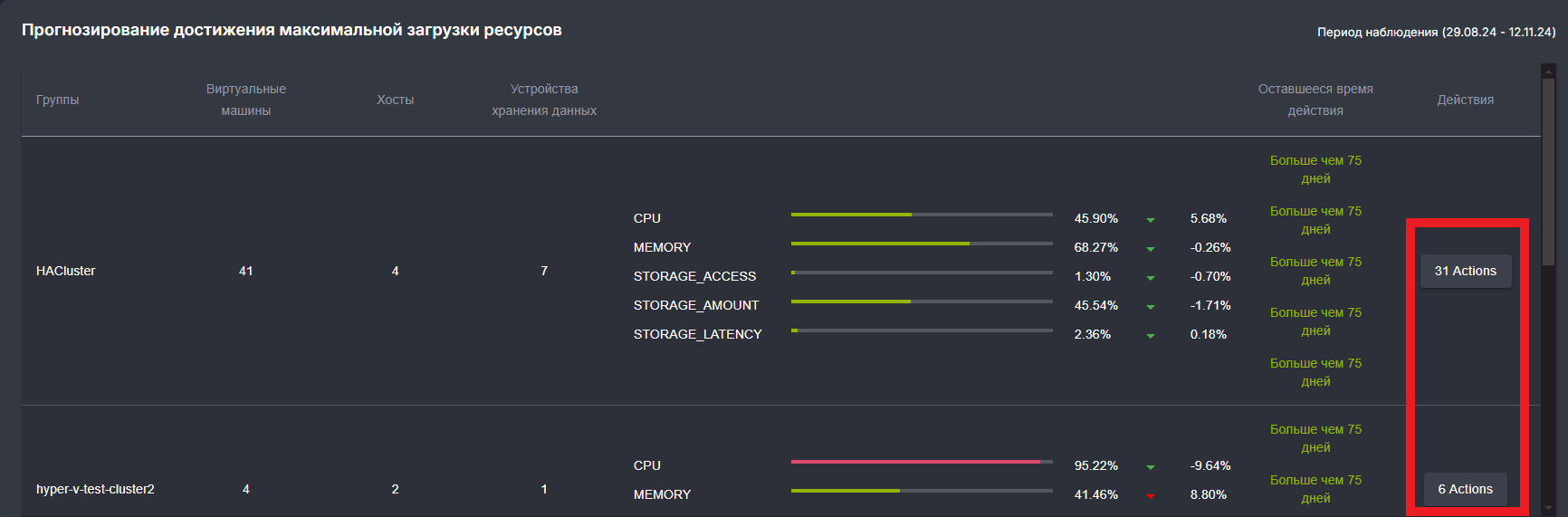
Прогнозирование достижения максимальной загрузки
Виджет используется для анализа и прогнозирования загрузки ресурсов. Он позволяет определить максимальную загрузку ресурсов каждого хоста и спрогнозировать дату ее достижения, чтобы заранее принять меры для оптимизации использования ресурсов и предотвращения перегрузки системы.
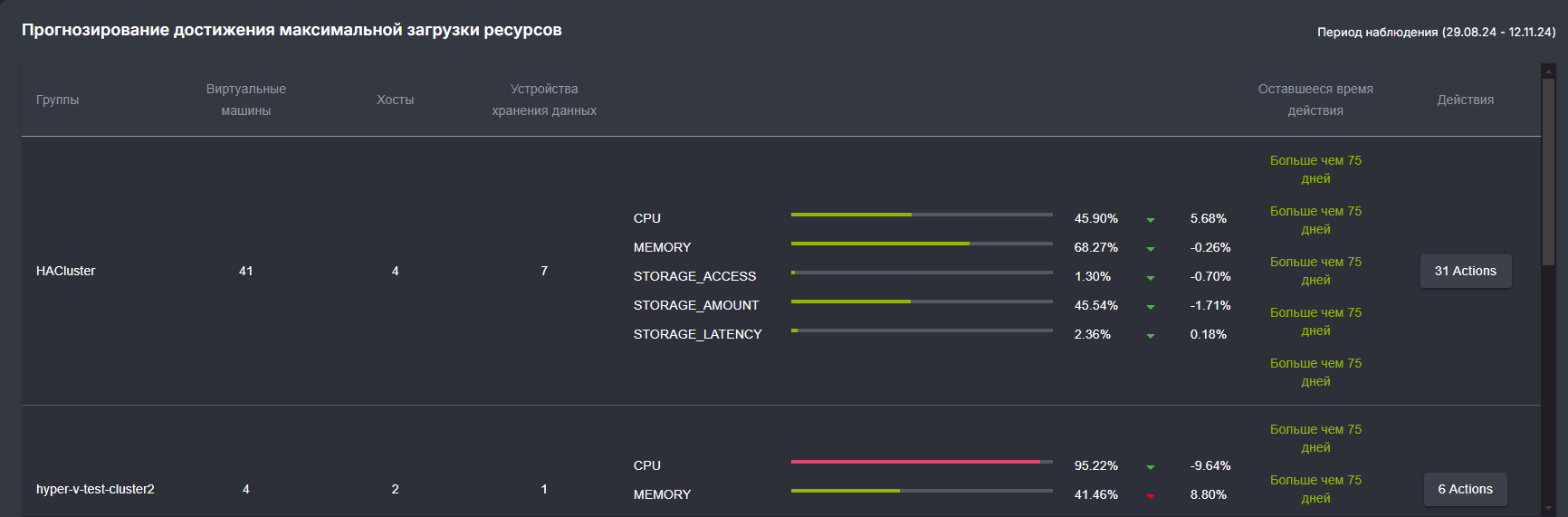
По умолчанию на виджете выводятся группы кластеров, которые собраны с подключенными таргетами. Для каждой группы отображаются содержащиеся в них количество ВМ, хостов и стораджей (запоминающих устройств).
В поле "Период наблюдения" (Observation period) можно выбрать конкретный временной период (неделя, месяц, год).
Для каждой выбранной группы отображается процентное соотношение загрузки по CPU, memory и storage_amount, где:
- первый процент - текущая загрузка ресурсов
- второй процент - изменение этой загрузки за период наблюдения
Прогресс-бар показывает степень загруженности ресурсов, цвета которых означают:
- красный цвет - критический уровень загруженности. На данный ресурс следует обратить внимание.
- желтый цвет - средний уровень загрузки.
- зеленый цвет - нормальный уровень загрузки.
Количество дней в колонке "Time to Exhaustion" показывает, когда (через сколько дней) первое значение дойдет до 100, т.е будет достигнута максимальная загрузка.
При нажатии на кнопку "Actions" открывается раздел графа со всеми доступными действиями для оптимизации ресурсов.
Выполненные действия (Completed actions)
Виджет содержит информацию об изменениях, которые были реализованы, а также здесь можно ознакомиться с результатами этих изменений и их влиянием на работу.

Виджет содержит вкладки:
- All (все) - выводит все выполненные рекомендации/действия
- Succeed - список всех успешно завершенных рекомендаций
- Failed - список всех рекомендаций, которые завершились с ошибкой